The Per-Seat Trap: Why AI Agents Break the SaaS Pricing Model

Throughout the SaaS era, enterprise software budgeting followed a simple formula: multiply licenses by headcount... and the resulting figure was considered an acceptable forecast, approved by the board without much debate.
But reality proved different altogether. Six months post forecast, the invoices told a different story: agents running overnight, token costs compounding invisibly, and usage bills arriving with no attribution and no warning.
The tool worked. The pricing model didn't.
This is the story of how per-seat licensing, the model that built a decade of enterprise SaaS, became the quiet reason most enterprise AI budgets in 2026 are unreliable and cannot be forecast accurately.
Per-seat licensing made sense for SaaS. It fails completely for AI agents. Here’s why enterprise AI budgets are blowing past projections.
Let's dive deeper into the pressing challenges enterprises face when trying to close the gap between SaaS pricing models and AI token economics and how MoolAI addresses them.
The Budget Shock Nobody Saw Coming
In 2026, two of the world’s most sophisticated technology organizations made the same expensive mistake.
Uber exhausted its entire annual AI budget in under four months; not because the tools failed, but because nobody had priced what it cost to run them at scale. Microsoft, watching compute bills outpace the productivity gains from its internal coding tools, pulled licenses that had been celebrated as a flagship AI investment just quarters earlier.
These were not reckless deployments or planning oversights. They were the predictable outcome of applying a pricing model built for one era of software to a fundamentally different one.
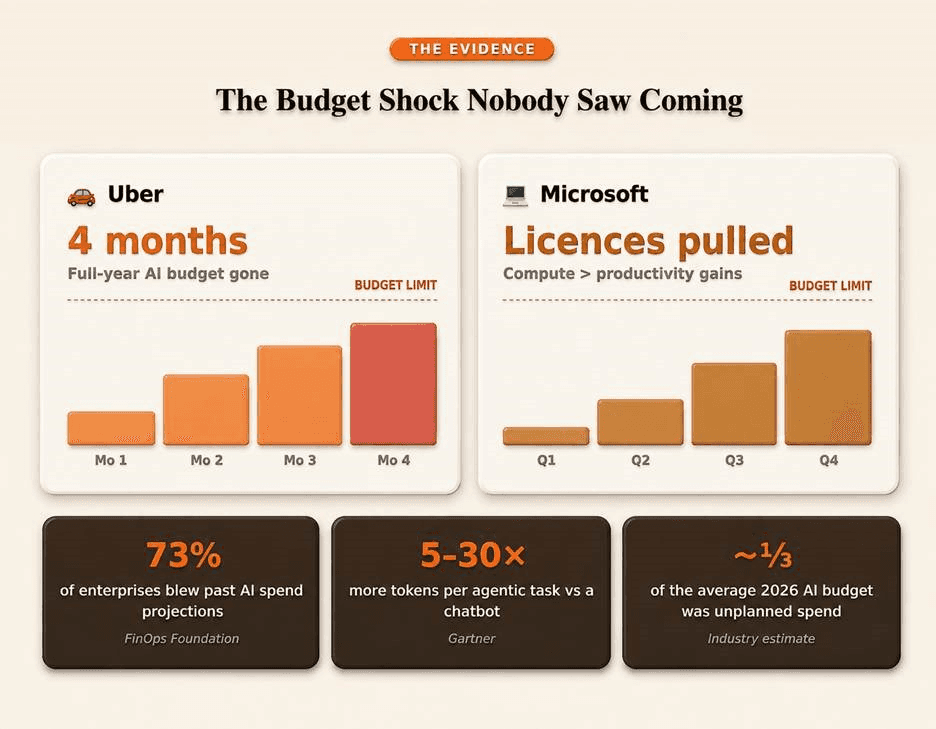
According to the latest FinOps Foundation survey, 73% of enterprises reported AI spend exceeding projections. The pattern is consistent enough to point to a structural problem and not a planning one. That structural problem is per-seat licensing.
The SaaS Seat Model — Why It Worked?
Per-seat licensing was a genuine innovation when it arrived with the SaaS wave. It replaced unpredictable enterprise software contracts that included perpetual licenses, maintenance fees, and version upgrade costs with something CFOs could manage: a fixed cost multiplied by headcount.
The model worked because the tools it priced were essentially static. A CRM seat gave one person access to a defined set of features. That person might log in every day or once a month; the cost was the same either way. Vendors loved predictability. Finance teams loved the forecastability. Procurement could benchmark it across vendors. Boards could approve it without squinting at appendices.
For a decade, per-seat pricing was the right answer to the right question - how many people need access to this tool?
AI agents ask a different question entirely.
How Agents Consume Differently - The Token Economics
When an employee uses a SaaS product, the cost to the vendor is essentially fixed — a thin slice of shared infrastructure. When an employee triggers an AI agent, the cost is a live inference event - model selection, context window size, number of reasoning steps, output length, and whether the agent loops back to correct itself.
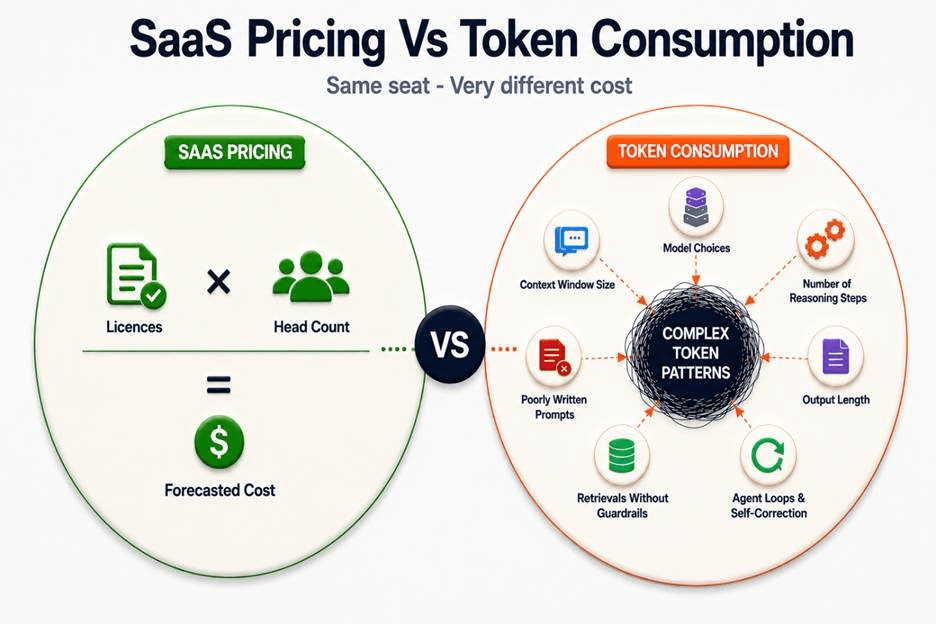
According to Gartner, a single agentic task today consumes 5 to 30 times the tokens of a basic chatbot interaction. That range matters. A developer running a code review agent all day is not consuming the same resource as a salesperson who asks a summarization agent one question each morning. Both hold the same seat. The cost gap between them can be a factor of fifty.
Token consumption is also sensitive to task design. A poorly written prompt that forces the model to retry. An agent connected to a large knowledge base with no retrieval of guardrails. A workflow that calls a premium model for a task that a smaller, cheaper model could handle. Each of these decisions — often made by individual contributors, not procurement teams and has a direct cost consequence that per-seat pricing was never designed to surface.
The seat counts stay flat for all quarters. The usage bill is not.
The Gap — What Per-Seat Pricing Can’t See
The deeper problem isn’t the cost itself. It’s invisibility.
Per-seat licensing, reports of access, not consumption.
Costs are not based on headcounts. They rely on the right prompts, the right agents, and optimized language models with guardrails applied.

The cost doesn’t reveal itself gradually. It arrives as an invoice itemized by vendor, not by workflow, user, or decision. By the time finance sees it, the spend has already happened. There is no mechanism to intervene, reallocate, or even understand what drove it.
This is the gap at the heart of enterprise AI in 2026: organizations licensed predictability and received a variable bill with no attribution. The number that justified, boardroom-friendly, benchmarked against headcount, was never the number that would be paid.
And because the gap is structural, a sharper dashboard reads after the fact doesn’t close it. Controls need to sit on the inference path before the money is spent.
How MoolAI Closes the Gap
MoolAI is built on the premise that AI cost control is not a reporting problem; it is a governance problem. The difference matters, because reporting tells you what happened. Governance determines what is allowed to happen.
MoolAI sits on the inference path between your agents and the models they call and apply three layers of control in real time.
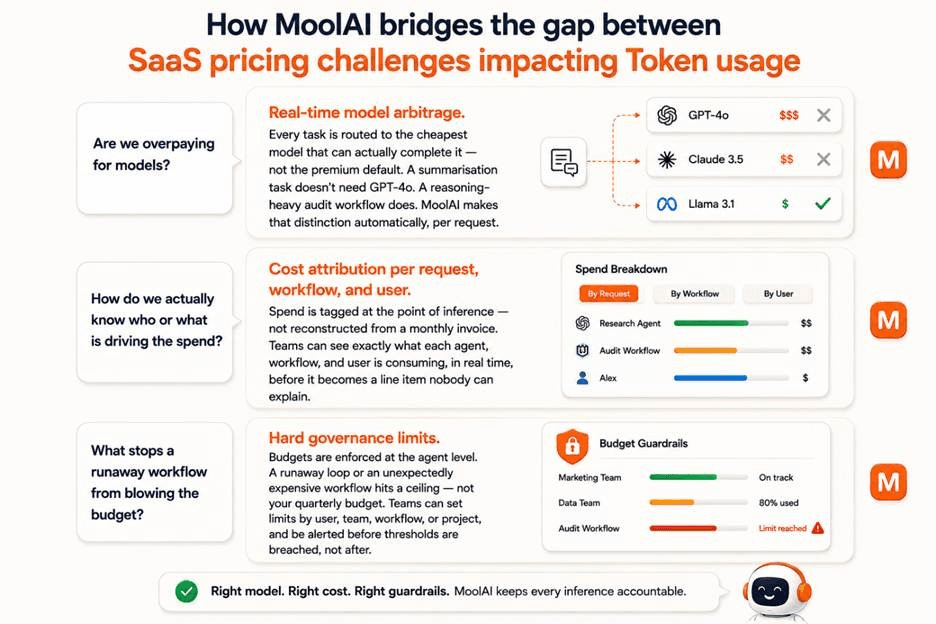
Together, these capabilities replace the per-seat promise — predictable, controllable spend — but deliver it to the actual cost structure of agentic AI. The agents that survive production won’t be the ones with the cleanest per-seat quote. They’ll be the ones whose cost can be seen and steered in real time, instead of explained in a meeting six weeks later.
Conclusion
Per-seat licensing was the right model for SaaS - fixed access, predictable cost, and clean headcount math. But AI agents don’t consume software. They consume inference, and inference is variable, unpredictable, and invisible inside a seat count. It is all about becoming aware before spend is committed, not after it is invoiced. That means real-time model routing, per-request attribution, and hard governance limits at the agent, workflow, and user level. Reporting is not enough; the intervention needs to happen where the cost is created.
MoolAI gives enterprises the visibility and control that legacy licensing was never designed to provide. The era of explaining AI overspending in hindsight is over. The question now is whether your infrastructure lets you steer in real time or only react after the invoice lands.
See how MoolAI gives your enterprise real-time control over AI inference costs. Mail to arun@moolai.ai for a demo
Build agents. Trust their outputs. Scale confidently.
Moolai ensures every AI agent is reliable, governed, and ready for enterprise deployment.
Book your Demo
